Table Design and Configuration
Iterators
Iterators are server-side programming mechanisms that encode functions such as filtering and aggregation within the data management steps (scopes where data is read from or written to disk) that happen in the tablet server.
Security labels
Accumulo Keys can contain a security label (called a Column Visibility) that enables expressive cell-level access control. Authorizations are passed with each query to control what data is returned to the user. Column visibilities support boolean AND and OR combinations of arbitrary strings (such as (A&B)|C) and authorizations are sets of strings (such as {C,D}).
Constraints
Constraints are configurable conditions where table writes are rejected. Constraints are written in Java and configurable on a per-table basis.
Sharding
Through the use of specialized iterators, Accumulo can be a parallel sharded document store. For example, Wikipedia could be stored and searched for documents containing certain words.
Large Rows
When reading rows, there is no requirement that an entire row fits into memory.
Namespaces
Table namespaces (since 1.6.0) allow for logical grouping and configuration of Accumulo tables. By default, tables are created in a default namespace which is the empty string to preserve the feel for how tables operate in previous versions. One application of table namespaces is placing the Accumulo root and metadata table in an “accumulo” namespace to denote that these tables are used internally by Accumulo.
Volume support
While Accumulo typically runs on a single HDFS instance, it supports multi-volume installations (since 1.6.0) which allow it to run over multiple disjoint HDFS instances and scale beyond the limits of a single namenode. When used in conjunction with HDFS federation, multiple namenodes can share a pool of datanodes.
Integrity/Availability
Manager fail over
Multiple managers can be configured. Zookeeper locks are used to determine which manager is active. The remaining managers simply wait for the current manager to lose its lock. Current manager state is held in the metadata table and Zookeeper.
Logical time
A mechanism to ensure that server set times never go backwards, even when time across the cluster is incorrect. This ensures that updates and deletes are not lost. If a tablet is served on machine with time a year in the future, then the tablet will continue to issue new timestamps a year in the future, even when it moves to another server. In this case the timestamps preserve ordering, but lose their meaning. In addition to logical time, Accumulo has manager authoritative time. The manager averages the time of all of the tablet servers and sends this back to the tablet servers. Tablet servers use this information to adjust the timestamps they issue. So logical time ensures ordering is always correct and manager authoritative time tries to ensure that timestamps are meaningful.
Logical Time for bulk import
Logical time as described above works with streaming (batch) ingest, where the tablet server assigns the timestamp. Logical time is also important for bulk imported data, for which the client code may be choosing a timestamp. Accumulo uses specialized system iterators to lazily set times in a bulk imported file. This mechanism guarantees that times set by unsynchronized multi-node applications (such as those running on MapReduce) will maintain some semblance of causal ordering. This mitigates the problem of the time being wrong on the system that created the file for bulk import. These times are not set when the file is imported, but whenever it is read by scans or compactions. At import, a time is obtained and always used by the specialized system iterator to set that time.
FATE
FATE (short for Fault Tolerant Executor) is a framework for executing operations in a fault tolerant manner. Before FATE, if the manager process died in the middle of creating a table it could leave the system in an inconsistent state. With this new framework, if the manager dies in the middle of create table it will continue on restart. Also, the client requesting the create table operation will never know anything happened. The framework serializes work in Zookeeper before attempting to do the work. Clients start a FATE transaction, seed it with work, and then wait for it to finish. Most table operations are executed using this framework. Persistent, per table, read-write locks are created in Zookeeper to synchronize operations across process faults.
Scalable manager
Stores its metadata in an Accumulo table and Zookeeper.
Isolation
Scans will not see data inserted into a row after the scan of that row begins.
Performance
Relative encoding
If consecutive keys have identical portions (row, colf, colq, or colvis), there is a flag to indicate that a portion is the same as that of the previous key. This is applied when keys are stored on disk and when transferred over the network. Starting with 1.5, prefix erasure is supported. When it is cost effective, prefixes repeated in subsequent key fields are not repeated.
Native In-Memory Map
By default, data written is stored outside of Java managed memory into a C++ STL map of maps. It maps rows to columns to values. This hierarchical structure improves performance of inserting a mutation with multiple column values in a single row. A custom STL allocator is used to avoid the global malloc lock and memory fragmentation.
Scan pipeline
A long running Accumulo scan will eventually cause multiple threads to start. One server thread to read data from disk, one server thread to serialize and send data, and one client thread to deserialize and read data. When pipelining kicks in, it substantially increases scan speed while maintaining key order. It does not activate for short scans.
Caching
Recently scanned data is cached into memory There are separate caches for indexes and data. Caching can be turned on and off for individual tables.
Multi-level RFile Index
RFiles store an index of the last key in each block. For large files, the index can become quite large. When the index is large, a lot of memory is consumed and files take a long time to open. To avoid this problem, RFiles have a multi-level index tree. Index blocks can point to other index blocks or data blocks. The entire index never has to be resident, even when the file is written. When an index block exceeds the configurable size threshold, it’s written out between data blocks. The size of index blocks is configurable on a per-table basis.
Binary search in RFile blocks
RFile uses its index to locate a block of key values. Once it reaches a block, it performs a linear scan to find a key of interest. Accumulo will generate indexes of cached blocks in an adaptive manner. Accumulo indexes the most frequently read blocks. When a block is read a few times, a small index is generated. As a block is read more, larger indexes are generated, making future seeks faster. This strategy allows Accumulo to dynamically respond to read patterns without precomputing block indexes when RFiles are written.
Testing
Mini Accumulo Cluster
Mini Accumulo cluster is a set of utility code that makes it easy to spin up a local Accumulo instance running against the local filesystem. Mini Accumulo is slower than Mock Accumulo, but its behavior mirrors a real Accumulo instance more closely.
Accumulo Maven Plugin
Using the Mini Accumulo Cluster in unit and integration tests is a great way for developers to test their applications against Accumulo in an environment that is much closer to physical deployments than a Mock Accumulo environment. Accumulo 1.6.0 also introduced a maven-accumulo-plugin which can be used to start a Mini Accumulo Cluster instance as a part of the Maven lifecycle that your application tests can use.
Functional Test
Small, system-level tests of basic Accumulo features run in a test harness, external to the build and unit-tests. These tests start a complete Accumulo instance, and require Hadoop and Zookeeper to be running. They attempt to simulate the basic functions of Accumulo, as well as common failure conditions, such as lost disks, killed processes, and read-only file systems.
Scale Test
A test suite that verifies data is not lost at scale. This test runs many ingest clients that continually create linked lists containing 25 million nodes. At some point the clients are stopped and a map reduce job is run to ensure no linked list has a hole. A hole indicates data was lost by Accumulo. The Agitator can be run in conjunction with this test to randomly kill tablet servers. This test suite has uncovered many obscure data loss bugs. This test also helps find bugs that impact uptime and stability when run for days or weeks.
Random Walk Test
A test suite that looks for unexpected system states that may emerge in plausible real-world applications. Application components are defined as test nodes (such as create table, insert data, scan data, delete table, etc.), and are programmed as Java classes that implement a specified interface. The nodes are connected together in a graph specified in an XML document. Many processes independently and concurrently execute a random walk of the test graphs. Some of the test graphs have a concept of correctness and can verify data over time. Other tests have no concept of data correctness and have the simple goal of crashing Accumulo. Many obscure bugs have been uncovered by this testing framework and subsequently corrected.
Client API[]
Batch Scanner
The BatchScanner takes a list of Ranges, batches them to the appropriate tablet servers, and returns data as it is received (i.e. not in sorted order).
Batch Writer
The BatchWriter client buffers writes in memory before sending them in batches to the appropriate tablet servers.
Bulk Import
Instead of writing individual mutations to Accumulo, entire files of sorted key value pairs can be imported using BulkImport. These files are moved into the Accumulo directory and referenced by Accumulo. This feature is useful for ingesting a large amount of data. This method of ingest usually offers higher throughput at the cost of higher latency for data availability for scans. Usually, the data is sorted using map reduce and then bulk imported. This method of ingest also allows for flexibility in resource allocation. The nodes running map reduce to sort data could be different from the Accumulo nodes.
MapReduce
Accumulo can be a source and/or sink for MapReduce jobs.
Proxy
Accumulo has a proxy which enables interaction to with Accumulo using other languages like Python, Ruby, C++, etc.
Conditional Mutations
Conditional Mutations (since 1.6.0) allow users to perform efficient, atomic read-modify-write operations on rows. Conditions can be defined using equality checks of the values in a column or the absence of a column. For more information on using this feature, users can reference the Javadoc for ConditionalMutation and ConditionalWriter.
Lexicoders
Lexicoders (since 1.6.0) help encode data (i.e numbers, dates) into Accumulo keys in a way that their natural sort order is preserved.
Plugins
The Service Plugin Interface (SPI) was created to expose Accumulo system level information to plugins in a stable manner.
Balancer
Users can provide a balancer plugin that decides how to distribute tablets across a table. These plugins can be provided on a per-table basis. This is useful for ensuring a particular table’s tablets are placed optimally for tables with special query needs. The default balancer randomly spreads each table’s tablets across the cluster. It takes into account where a tablet was previously hosted to leverage locality. When a tablet splits, the default balancer moves one child to another tablet server. The assumption here is that splitting tablets are being actively written to, so this keeps write load evenly spread.
Cache
See the page on Caching
Compaction
Compactions were reworked in 2.1 to allow plugin capabilities. See the documentation for compactions.
Scan
Scan Executors were added to the SPI in 2.0. See the Scan Executors page.
Volume Chooser
The Volume Chooser has been around for some time but was refactored in 2.1 to be included in the SPI. See the javadoc for more information.
Pluggable Block Caches
Accumulo provides two BlockCacheManager implementations (LruBlockCacheManager and TinyLfuBlockCacheManager) that construct on-heap block caches. Users can provide alternate BlockCacheManager implementations using the property tserver.cache.manager.class.
General Administration
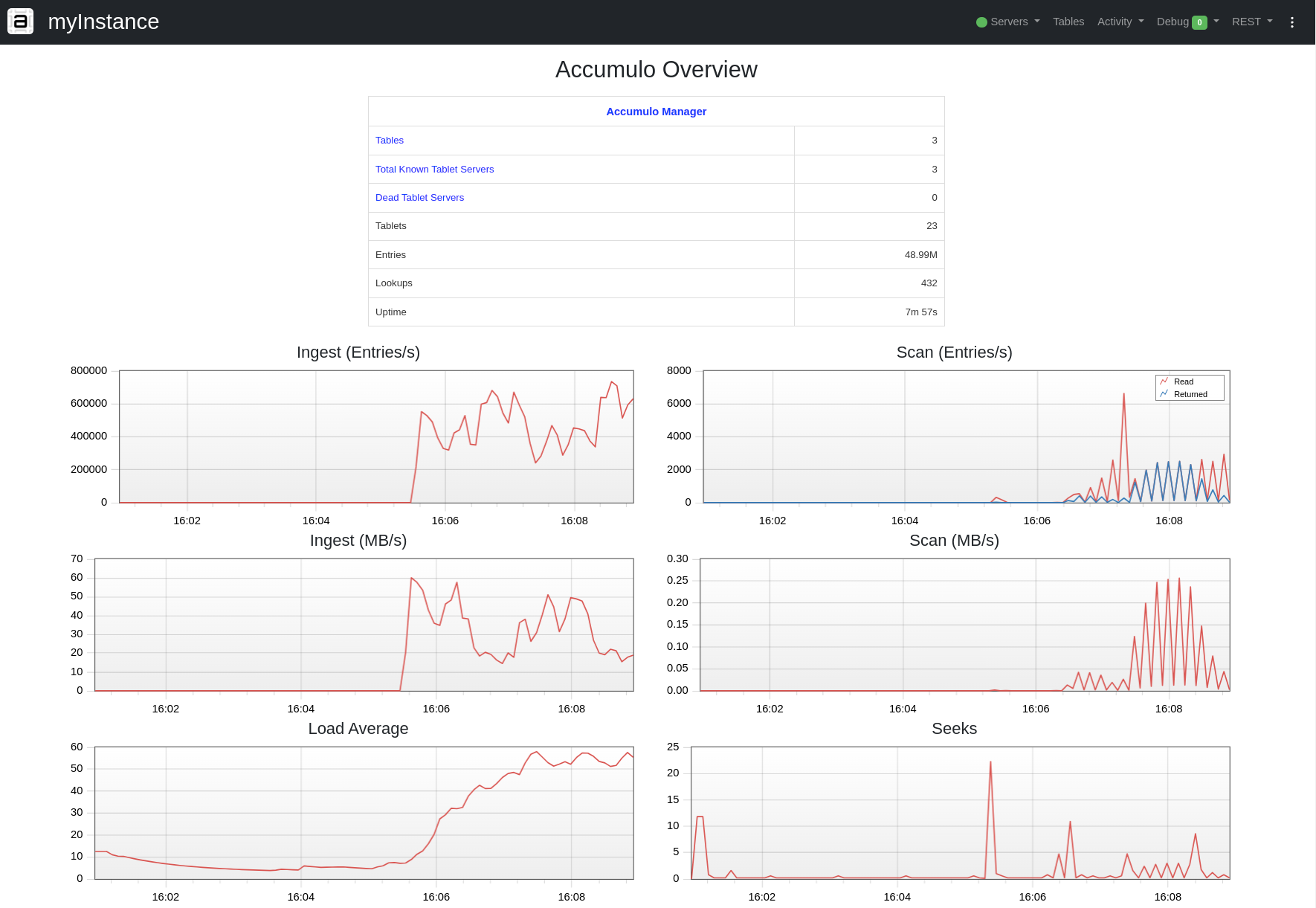
Monitor page
The Accumulo Monitor provides basic information about the system health and performance. It displays table sizes, ingest and query statistics, server load, and last-update information. It also allows the user to view recent diagnostic logs and traces.
Tracing
It can be difficult to determine why some operations are taking longer than expected. For example, you may be looking up items with very low latency, but sometimes the lookups take much longer. Determining the cause of the delay is difficult because the system is distributed, and the typical lookup is fast. Accumulo has been instrumented to record the time that various operations take when tracing is turned on. The fact that tracing is enabled follows all the requests made on behalf of the user throughout the distributed infrastructure of Accumulo, and across all threads of execution.
Online reconfiguration
System and per table configuration is stored in Zookeeper. Many, but not all, configuration changes take effect while Accumulo is running. Some do not take effect until server processes are restarted.
Table renaming
Tables can be renamed easily because Accumulo uses internal table IDs and stores mappings between names and IDs in Zookeeper.
Internal Data Management
Locality groups
Groups columns within a single file. There is a default locality group so that not all columns need be specified. The locality groups can be restructured while the table is online and the changes will take effect on the next compaction. A tablet can have files with different locality group configurations. In this case, scans may be suboptimal, but correct until compactions rewrite all files. After reconfiguring locality groups, a user can force a table to compact in order to write all data into the new locality groups. Alternatively, the change could be allowed to happen over time as writes to the table cause compactions to happen.
Smart compaction algorithm
It is inefficient to merge small files with large files. Accumulo merges files only if all files are larger than a configurable ratio (default is 3) multiplied by the largest file size. If this cannot be done with all the files, the largest file is removed from consideration, and the remaining files are considered for compaction. This is done until there are no files to merge.
Encryption
Accumulo can encrypt its data on disk and data sent over the wire.
On-demand Data Management
Compactions
Ability to force tablets to compact to one file. Even tablets with one file are compacted. This is useful for improving query performance, permanently applying iterators, or using a new locality group configuration. One example of using iterators is applying a filtering iterator to remove data from a table. Additionally, users can initiate a compaction with iterators only applied to that compaction event.
Split points
Arbitrary split points can be added to an online table at any point in time. This is useful for increasing ingest performance on a new table. It can also be used to accommodate new data patterns in an existing table.
Tablet Merging
Tablet merging is a new feature. Merging of tablets can be requested in the shell; Accumulo does not merge tablets automatically. If desired, the METADATA tablets can be merged.
Table Cloning
Allows users to quickly create a new table that references an existing table’s data and copies its configuration. A cloned table and its source table can be mutated independently. Testing was the motivating reason behind this new feature. For example, to test a new filtering iterator, clone the table, add the filter to the clone, and force a major compaction.
Import/Export Table
An offline tables metadata and files can easily be copied to another cluster and imported.
Compact Range
Compact each tablet that falls within a row range down to a single file.
Delete Range
Added an operation to efficiently delete a range of rows from a table. Tablets that fall completely within a range are simply dropped. Tablets overlapping the beginning and end of the range are split, compacted, and then merged.
